



为了详细了解Prompt Engineering,本部分内容对NLP中大语言模型至今的一些发展做了详细介绍。在此过程中,读者可以了解到,prompt这个概念是如何诞生,并且变得如此重要的。了解这些基础知识,有助于我们更好地发挥prompt优化任务的潜力。
Transformer模型:LLMs的根基
NLP发展至今,基于机器学习算法逐步延伸出独特的算法方向。
在机器学习中,通常将语句拆分为词,统计词间关系、出现频率、TF-IDF等特征,通过这些特征构建特征矩阵,以将其转化为机器能够处理的结构化数据。
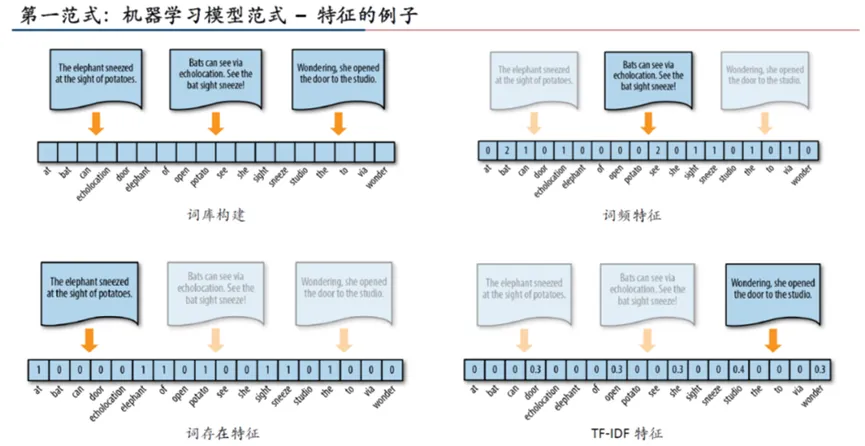
在构建特征矩阵后,下一步通常是训练模型和对测试数据进行分类或预测。
深度学习通常通过多层次的非线性转换来进行自动的特征提取,最常用的模型为CNN(卷积神经网络)。CNN被广泛用于图像识别等领域;但在自然语言处理领域,效果不够好。这是因为语言的表达并非单纯沿着某个方向进行,上下文之间是互相影响的。为了将这种上下文(context)影响计算进来,RNN(循环神经网络)从多个方向进行循环计算。但这又带来大量的算力要求,后来引入了 注意力(Attention)机制 ,只对最关键的点提高算力,其他地方则进行简化,这带来了不错的效果。
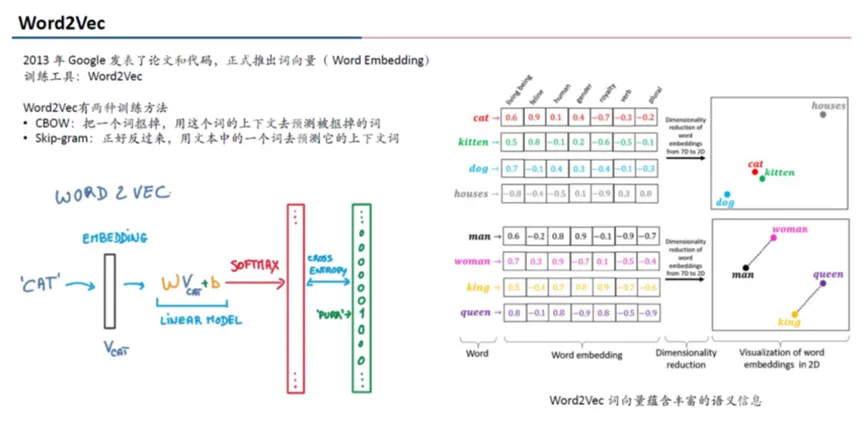
利用Word2Vec将词按某些规则变为向量,自然语言的各类特征就成为了词向量之间的关系;利用RNN+Attention,训练者无需手动统计这些特征,只需对应参数输出结果和想要的输出接近一致即可。
2017年6月,Google 发表论文 Attention is All You Need, 提出Transformer 模型。基于RNN和Self-Attention机制,Transformer将输入序列通过Encoder进行特征提取,并用Decoder将其映射为目标序列。自注意力机制能确保Transformer推导输入序列中的关键词,编码器-解码器架构则带来了极强的可扩展性,使其在自然语言处理、机器翻译等领域带来重大突破。
Transformer模型的提出,是NLP发展的一座里程碑,成为了目前几乎所有LLM模型的底层算法。以BERT和GPT为典型。BERT和GPT的区别优化目标上:BERT采用的是 Mask Language Model ,即mask掉一个句子中的某些token,利用句子中其他token预测;而GPT采用的是Autoregressive Language Model,即 利用前面的单词预测下一个单词 ,是一个典型的语言模型。
GPT-1:预训练模型
GPT-1基于Transformer提出了无监督语言模型的“预训练+finetune”架构,即先在大规模无监督语料上,以语言模型为目标进行预训练,再利用已经训练好的模型在下游任务行finetune。
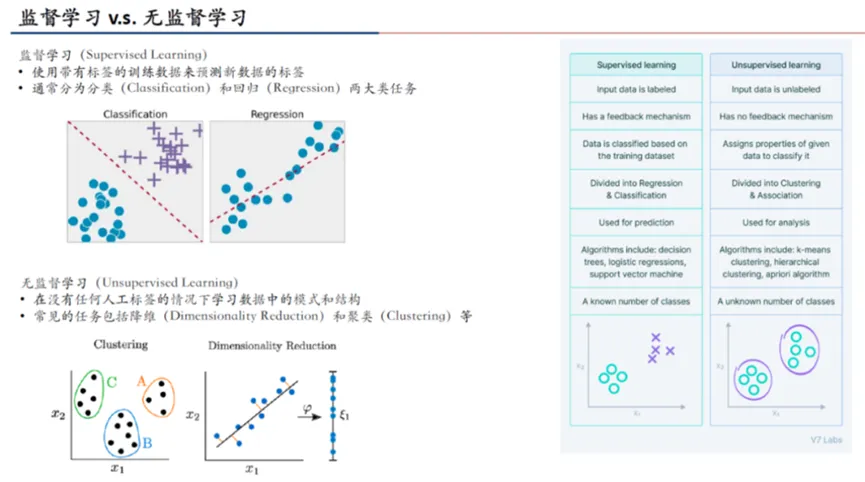
无监督学习是机器学习的主要方式之一(监督学习需要带标签数据),通常用于聚类、降维、模型优化等任务。相对监督学习来说,由于无需人工标注,所以成本上更占优势。在GPT-1之前,NLP中的无监督预训练就已经有比较久的历史了。
在GPT之前,所有模型都是现训练的,为了训练一个针对特定下游任务的模型,需要大量的标注数据和计算资源,并且难以实现模型共享;GPT则提出预训练的概念,即使用不同的预训练任务和数据集对模型进行提前训练,最后通过微调的方式来对下游任务进行定制。
预训练模型的发展历程大致如下:
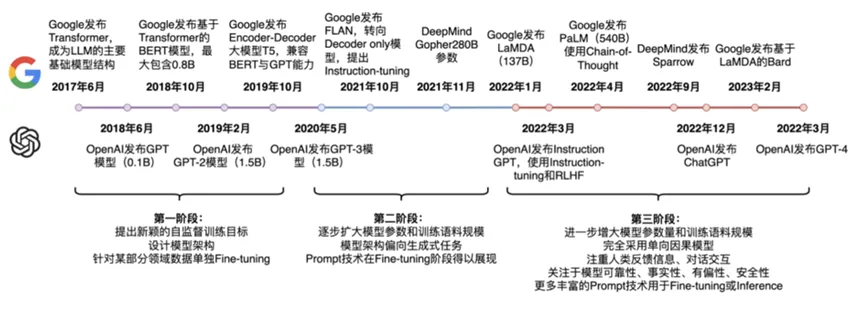
由于BERT相对于GPT-1参数数量级的碾压,2018年GPT-1与BERT相继问世后,后续大量模型几乎是直接拿BERT去做微调。
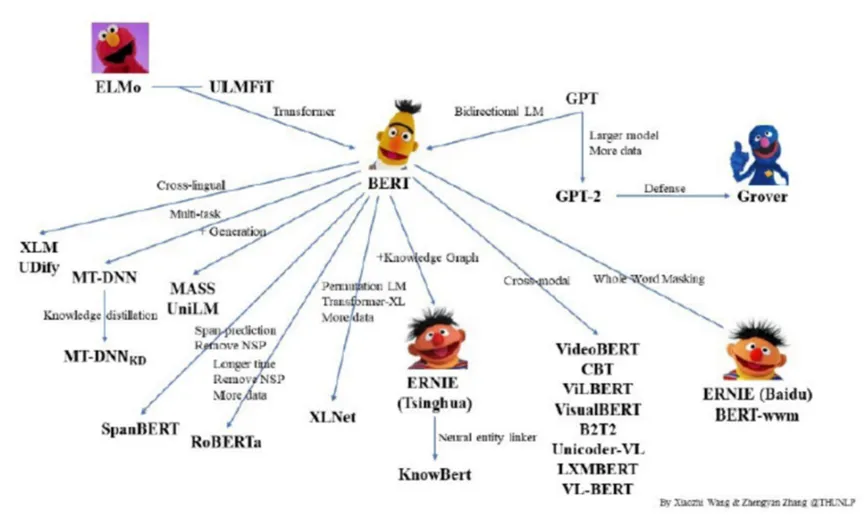
GPT-2:初见端倪的prompt
BERT和GPT提出后,预训练语言模型开始朝”大“的方向发展:更多的训练数据、更大的模型尺寸。因此,GPT-2和GPT-1的一个基本差异是预训练的无监督数据用的更多了、质量更高了,模型的体积也更大了(GPT-2拥有15.4亿个参数,48层)。
GPT-2的另一个重点是提出了zero-shot learning的思路。GPT-2强调,在进行无监督预训练语言模型训练的过程中,模型即使没有加入任何下游任务的信息,模型也已经在学习下游任务了。语言模型这个优化目标,即包含下游所有NLP任务。
GPT-2是GPT-1和GPT-3的一个过渡,GPT-2开始认真思考这样一个问题:是否所有的NLP任务都是语言模型的一个子集?如何在不使用下游任务数据训练的情况下,以zero-shot的方式让下游任务来适应预训练语言模型?从2019年开始,OpenAI逐渐将prompt的概念引入到GPT-2中,使得用户可以更方便控制模型的生成结果。正是这些思路的延续,才出现了后续的GPT — — 基于prompt和in-context learning的NLP新方法 。
GPT-3:“预训练+提示+预测”
GPT-3使用了1750亿的模型参数。其仍然是沿着GPT-2的思路,思考如何让下游任务更好的适配预训练语言模型,打破原有的pretrain+finetune架构。
**GPT-3提出的In-context learning的思路,指的是预训练语言模型不需要在下游任务上finetune,而是通过prompt的设计,让下游任务适配到预训练语言模型中,给出合适的回答。**在zero-shot中,直接将任务描述和prompt文本输入到模型中,再将语言模型预测出的的文本映射到答案上。而few-shot、one-shot中,则是在此基础上,再输入一些任务的例子,以文本的形式拼接到一起,输入到语言模型中。
随着模型参数越来越多,单次训练的成本也愈发昂贵。GPT-3逐步形成了与以往“预训练+finetune”、让模型去迁就下游任务的模式不同的思路,使用prompt(提示)方法将下游任务进行微调/重构,以达到大模型最佳输出的要求。
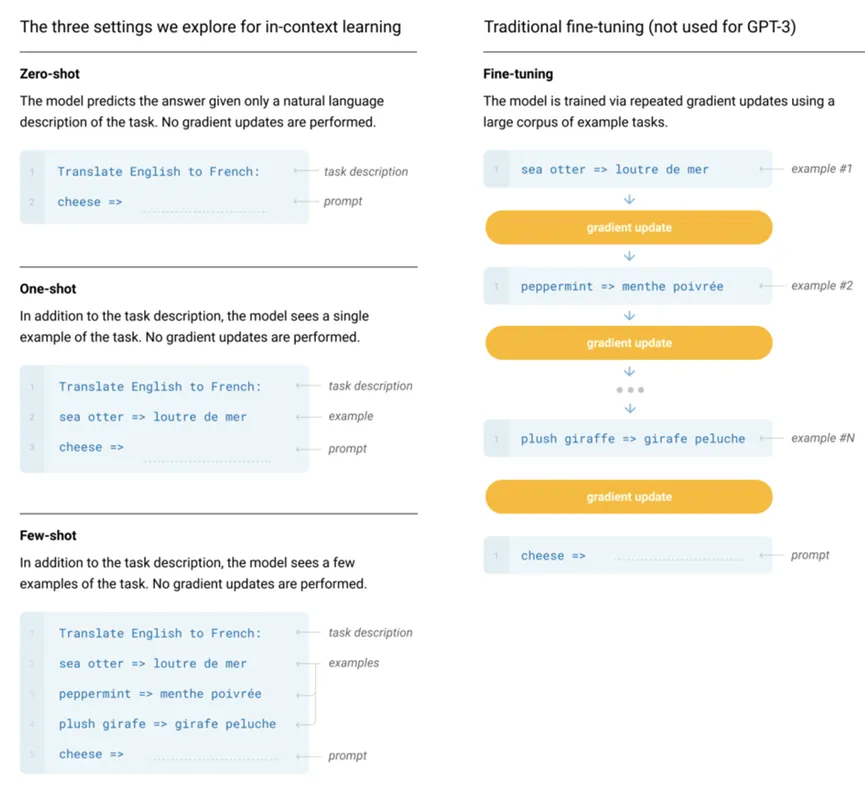
GPT-3也掀起了一波大型语言模型(LLM)的浪潮。这些LLMs大多是包含数千亿(或更多)参数的语言模型,例如GPT-3、PaLM、Galactica 和 LLaMA等。
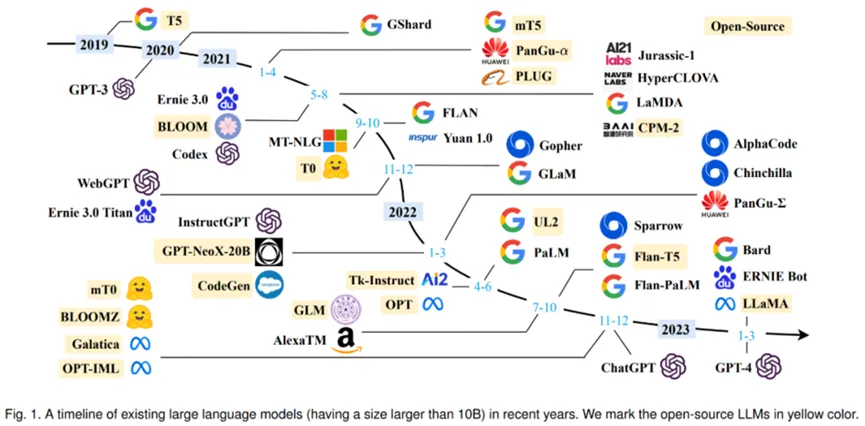
2019 年以来出现的各种大语言模型(百亿参数以上)时间轴,其中标黄的大模型已开源。
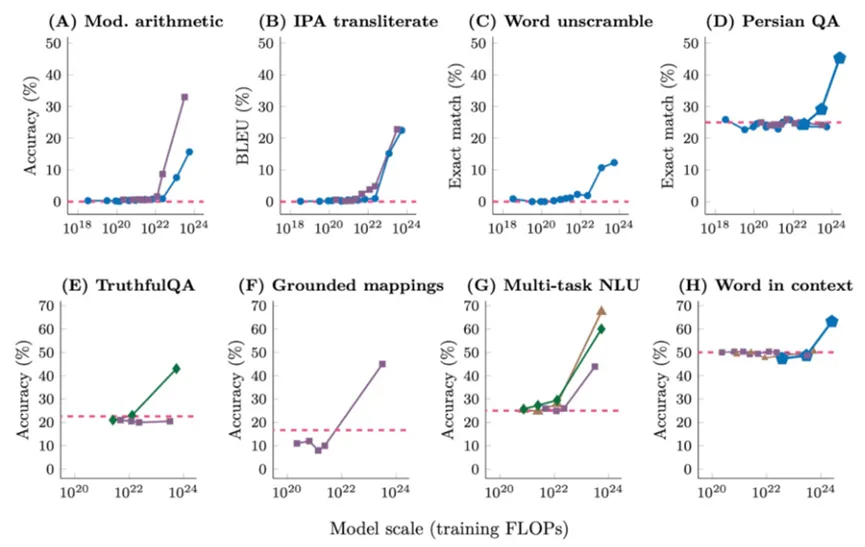
现有的 LLM 主要采用与小语言模型类似的模型架构,作为主要区别,LLM 在很大程度上扩展了模型大小、预训练数据和总计算量。随着参数量和训练数据量的增大,语言模型的能力会随着参数量的指数增长而线性增长,这种现象被称为Scaling Law(下图左例)。但是随着进来对大模型的深入研究,人们发现当模型的参数量大于一定程度的时候,模型能力会突然暴涨,模型会突然拥有一些突变能力(Emergent Ability,涌现),如上下文学习、推理能力等。
InstructGPT:引入强化学习训练
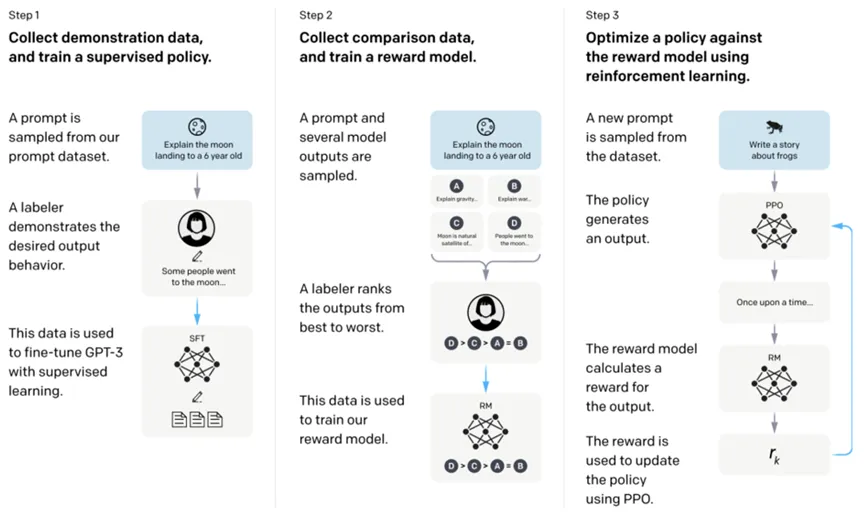
InstructGPT是在GPT-3的基础上进行改良的,可以利用指令式控制生成来提高生成结果的质量和多样性。其核心是如何让GPT生成的回答更符合人类的需求,核心是引入了 RLHF强化学习训练(reinforcement learning from human feed-back) 。
RLHF基于强化学习的思想去优化无监督预训练模型产出的文本,让其更符合人类的需求。整个RLHF过程分为3个主要步骤。
在进行RLHF之前,需要先得到一个无监督样本行预训练的GPT模型。接下来第一步【监督学习】是根据一些prompt,让人去生成高质量的回答,GPT在这些人工生成数据上进行有监督的finetune,让GPT初步具备根据问题产出符合人类标准的文本的能力。
第二步【奖励模型】是训练一个reward model。Reward model是强化学习中的一个核心概念,它可以用来评价agent的一次行动的奖励是多少,并以此为信号指导agent的学习。比如一个AI汽车发下前面有一块石头,它进行了避让,reward model就会给其一个正的reward,强化agent的这次行为;相反,如果遇到石头AI汽车直接冲了过去,reward model就给其一个负的reward。通过这种方式,reward model可以指导模型的学习,以达到我们期望的目标。
Reward model的训练也是基于大量的人工标注数据。首先第一步给finetune后的GPT提一个prompt,GPT会产生一些答案,让人对这些答案进行标注,按照人类的标准进行好中差的排序,这个数据就被用来训练一个reward model。
第三步【模型微调】,有了reward model,整个强化学习的逻辑就能自动跑起来了。给一个prompt,GPT生成一个答案,reward model给这个答案打个分,这个分用来更新GPT的参数。通过这种方式,让GPT在第三步的学习过程中,不断朝着人类希望的标准优化。
GPT-3.5:继往开来
GPT-3.5是一系列GPT模型的统称,如下图:
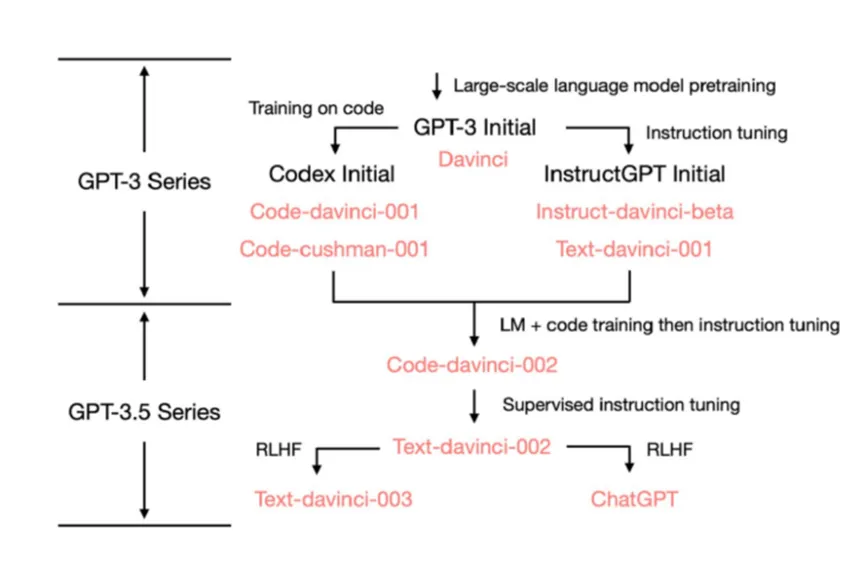
而GPT-3.5-turbo*就是我们常说的chatGPT。本文为尝试了解GPT原理所整理的一个学习笔记,至于GPT-4令人惊艳的插件、多模态等,大致逻辑我想和前述应该一致,具体细节闭源也学不到、就算绑在我脸上我也学不会,就算了。


评论区